| 2018 | |
 |
 MobiLimb: Augmenting Mobile Devices with a Robotic Limb
MobiLimb: Augmenting Mobile Devices with a Robotic Limb. In UIST'18: Proceedings of the ACM Symposium on User Interface Software and Technology, ACM (2018). 53-63. 

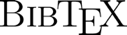
@inproceedings{MT:UIST-18,
keywords
author = M. {Teyssier} and G. {Bailly} and C. {Pelachaud} and E. {Lecolinet}, booktitle = UIST'18: Proceedings of the ACM Symposium on User Interface Software and Technology, month = oct, pages = 53--63, publisher = ACM, title = MobiLimb: Augmenting Mobile Devices with a Robotic Limb, year = 2018, image = mobilimb-UIST18.png, link = https://uist.acm.org/uist2018/, project = https://www.marcteyssier.com/projects/mobilimb/, video = https://www.youtube.com/watch?v=wi3INyIDNdk, } Mobile device, Actuated devices, Robotics, Mobile Augmentation
abstract
In this paper, we explore the interaction space of MobiLimb, a small 5-DOF serial robotic manipulator attached to a mobile device. It (1) overcomes some limitations of mobile devices (static, passive, motionless); (2) preserves their form factor and I/O capabilities; (3) can be easily attached to or removed from the device; (4) offers additional I/O capabilities such as physical deformation and (5) can support various modular elements such as sensors, lights or shells. We illustrate its potential through three classes of applications: As a tool, MobiLimb offers tangible affordances and an expressive con- troller that can be manipulated to control virtual and physical objects. As a partner, it reacts expressively to users' actions to foster curiosity and engagement or assist users. As a medium, it provides rich haptic feedback such as strokes, pat and other tactile stimuli on the hand or the wrist to convey emotions during mediated multimodal communications.
link
project |
 |
Impact of Semantic Aids on Command Memorization for On-Body Interaction and Directional Gestures . In AVI'18: International Conference on Advanced Visual Interfaces, Article No. 14 (9 pages), ACM (2018).

@inproceedings{BL:AVI-18,
keywords
address = Grosseto, Italie, author = B. {Fruchard} and E. {Lecolinet} and O. {Chapuis}, booktitle = AVI'18: International Conference on Advanced Visual Interfaces, month = jun, number = Article No. 14 (9 pages), publisher = ACM, title = Impact of Semantic Aids on Command Memorization for On-Body Interaction and Directional Gestures, year = 2018, hal = hal-01764757, image = bodyloci-AVI18.png, link = https://sites.google.com/dis.uniroma1.it/avi2018/, video = https://vimeo.com/251815791, } Semantic aids; Memorization; Command selection; On-body interaction; Marking menus; Virtual reality
abstract
Previous studies have shown that spatial memory and semantic aids can help users learn and remember gestural commands. Using the body as a support to combine both dimensions has therefore been proposed, but no formal evaluations have yet been reported. In this paper, we compare, with or without semantic aids, a new on-body interaction technique (BodyLoci) to mid-air Marking menus in a virtual reality context. We consider three levels of semantic aids: no aid, story-making, and story-making with background images. Our results show important improvement when story-making is used, especially for Marking menus (28.5% better retention). Both techniques performed similarly without semantic aids, but Marking menus outperformed BodyLoci when using them (17.3% better retention). While our study does not show a benefit in using body support, it suggests that inducing users to leverage simple learning techniques, such as story-making, can substantially improve recall, and thus make it easier to master gestural techniques. We also analyze the strategies used by the participants for creating mnemonics to provide guidelines for future work.
link |
| 2017 | |
 |
MarkPad: Augmenting Touchpads for Command Selection . In CHI'17: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2017). 5630-5642.
@inproceedings{MP:CHI-17,
keywords
address = Denver, Colorado, Etats-Unis, author = B. {Fruchard} and E. {Lecolinet} and O. {Chapuis}, booktitle = CHI'17: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = may, pages = 5630--5642, publisher = ACM, title = MarkPad: Augmenting Touchpads for Command Selection, year = 2017, hal = hal-01437093/en, image = MP-CHI-17.png, link = https://chi2017.acm.org/, project = http://brunofruchard.com/markpad.html, video = https://www.youtube.com/watch?v=rUGGTrYPuSM, software = http://brunofruchard.com/markpad.html, } Gestural interaction; bezel gestures; tactile feedback; spatial memory; touchpad; user-defined gestures; Marking menus
abstract
We present MarkPad, a novel interaction technique taking advantage of the touchpad. MarkPad allows creating a large number of size-dependent gestural shortcuts that can be spatially organized as desired by the user. It relies on the idea of using visual or tactile marks on the touchpad or a combination of them. Gestures start from a mark on the border and end on another mark anywhere. MarkPad does not conflict with standard interactions and provides a novice mode that acts as a rehearsal of the expert mode. A first study showed that an accuracy of 95% could be achieved for a dense configuration of tactile and/or visual marks allowing many gestures. Performance was 5% lower in a second study where the marks were only on the borders. A last study showed that borders are rarely used, even when the users are unaware of the technique. Finally, we present a working prototype and briefly report on how it was used by two users for a few months.
link
project
software |
 |
CoReach: Cooperative Gestures for Data Manipulation on Wall-sized Displays . In CHI'17: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2017). 6730-6741.
@inproceedings{LCBL:CHI-17,
keywords
author = C. {Liu} and O. {Chapuis} and M. {Beaudouin-Lafon} and E. {Lecolinet}, booktitle = CHI'17: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = may, pages = 6730--6741, publisher = ACM, title = CoReach: Cooperative Gestures for Data Manipulation on Wall-sized Displays, year = 2017, hal = hal-01437091/en, image = LCBL-CHI-17.jpg, link = https://chi2017.acm.org/, video = https://www.lri.fr/~chapuis/publications/CHI17-coreach.mp4, } Shared interaction, wall display, co-located collaboration
abstract
Multi-touch wall-sized displays afford collaborative exploration of large datasets and re-organization of digital content. However, standard touch interactions, such as dragging to move content, do not scale well to large surfaces and were not designed to support collaboration, such as passing an object around. This paper introduces CoReach, a set of collaborative gestures that combine input from multiple users in order to manipulate content, facilitate data exchange and support communication. We conducted an observational study to inform the design of CoReach, and a controlled study showing that it reduced physical fatigue and facilitated collaboration when compared with traditional multi-touch gestures. A final study assessed the value of also allowing input through a handheld tablet to manipulate content from a distance.
link |
 |
BIGnav: Bayesian Information Gain for Guiding Multiscale Navigation . In CHI'17: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2017). 5869-5880. CHI 2017 Best Paper Award.

@inproceedings{BN:CHI-17,
keywords
address = Denver, Colorado, USA, author = W. {Liu} and R. {Lucas DOliveira} and M. {Beaudouin-Lafon} and O. {Rioul}, booktitle = CHI'17: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = may, pages = 5869--5880, publisher = ACM, title = BIGnav: Bayesian Information Gain for Guiding Multiscale Navigation, url = https://youtu.be/ThDzB5ewbZM, year = 2017, award = CHI 2017 Best Paper Award, image = BN-CHI-17.jpg, link = https://chi2017.acm.org/, video = https://youtu.be/N2P-LFh1oLk, video-preview = https://youtu.be/ThDzB5ewbZM, } Multiscale navigation; Guided navigation; Bayesian experimental design; Mutual information
abstract
This paper introduces BIGnav, a new multiscale navigation technique based on Bayesian Experimental Design where the criterion is to maximize the information-theoretic concept of mutual information, also known as information gain. Rather than simply executing user navigation commands, BIGnav interprets user input to update its knowledge about the user's intended target. Then it navigates to a new view that maximizes the information gain provided by the user's expected subsequent input. We conducted a controlled experiment demonstrating that BIGnav is significantly faster than conventional pan and zoom and requires fewer commands for distant targets, especially in non-uniform information spaces. We also applied BIGnav to a realistic application and showed that users can navigate to highly probable points of interest on a map with only a few steps. We then discuss the tradeoffs of BIGnav including efficiency vs. increased cognitive load and its application to other interaction tasks.
link |
 |
IconHK: Using Toolbar button Icons to Communicate Keyboard Shortcuts . In CHI'17: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2017). 4715-4726.
@inproceedings{ICHK:CHI-17,
keywords
address = Denver, Colorado, Etats-Unis, author = E. {Giannisakis} and G. {Bailly} and S. {Malacria} and F. {Chevalier}, booktitle = CHI'17: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = may, pages = 4715--4726, publisher = ACM, title = IconHK: Using Toolbar button Icons to Communicate Keyboard Shortcuts, year = 2017, hal = hal-01444365, image = iconhk.gif, link = https://chi2017.acm.org/, video = https://www.youtube.com/watch?v=ZzLASYkt6qc, } Icons; keyboard shortcuts; hotkeys; GUI design
abstract
We propose a novel perspective on the design of toolbar but- tons that aims to increase keyboard shortcut accessibility. IconHK implements this perspective by blending visual cues that convey keyboard shortcut information into toolbar buttons without denaturing the pictorial representation of their command. We introduce three design strategies to embed the hotkey, a visual encoding to convey the modifiers, and a magnification factor that determines the blending ratio between the pictogram of the button and the visual representation of the keyboard shortcut. Two studies examine the benefits of IconHK for end-users and provide insights from professional designers on the practicality of our approach for creating iconsets. Building on these insights, we develop a tool to assist designers in applying the IconHK design principle.
link |
 |
VersaPen: An Adaptable, Modular and Multimodal I/O Pen . In CHI'17 Extended Abstracts: ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2017). 2155-2163.
@inproceedings{Teyssier:VersaPen-2017,
keywords
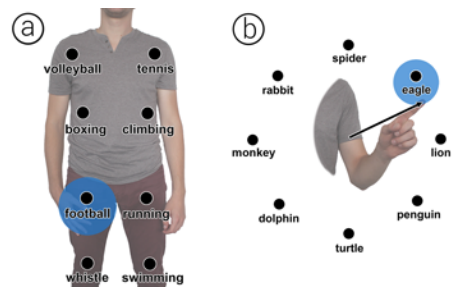
address = Denver, USA, author = M. {Teyssier} and G. {Bailly} and E. {Lecolinet}, booktitle = CHI'17 Extended Abstracts: ACM SIGCHI Conference on Human Factors in Computing Systems, month = may, pages = 2155--2163, publisher = ACM, title = VersaPen: An Adaptable, Modular and Multimodal I/O Pen, year = 2017, hal = hal-01521565, image = VersaPen-wp-CHI17.png, link = https://chi2017.acm.org/, video = https://www.youtube.com/watch?v=WhhZc67geAQ, } Pen input; Multimodal interaction; Modular input
abstract
While software often allows user customization, most physical devices remain mainly static. We introduce VersaPen, an adaptable, multimodal, hot-pluggable pen for expanding input capabilities. Users can create their own pens by stacking different input/output modules that define both the look and feel of the customized device. VersaPen offers multiple advantages. Allowing in-place interaction, it reduces hand movements and avoids cluttering the interface with menus and palettes. It also enriches interaction by providing multimodal capabilities, as well as a mean to encapsulate virtual data into physical modules which can be shared by users to foster collaboration. We present various applications to demonstrate how VersaPen enables new interaction techniques.
link |
 |
VersaPen: Exploring Multimodal Interactions with a Programmable Modular Pen . In CHI'17 Extended Abstracts (demonstration): ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2017). 377-380.
@inproceedings{teyssier:hal-01521566,
keywords
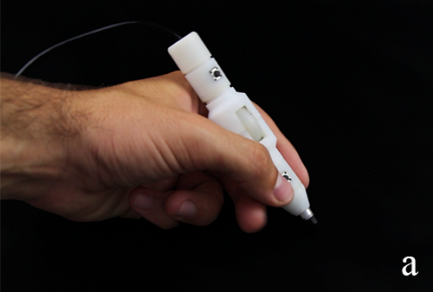
address = Denver, USA, author = M. {Teyssier} and G. {Bailly} and E. {Lecolinet}, booktitle = CHI'17 Extended Abstracts (demonstration): ACM SIGCHI Conference on Human Factors in Computing Systems, month = may, pages = 377--380, publisher = ACM, title = VersaPen: Exploring Multimodal Interactions with a Programmable Modular Pen, year = 2017, hal = hal-01521566, image = VersaPen-demo-CHI17.png, link = https://chi2016.acm.org/, video = https://www.youtube.com/watch?v=LYIjfUDTdbU, } Pen input ; Multimodal interaction
abstract
We introduce and demonstrate VersaPen, a modular pen for expanding input capabilities. Users can create their own digital pens by stacking different input/output modules that define both the look and feel of the customized device. VersaPen investigate the benefits of adaptable devices and enriches interaction by providing multimodal capabilities, allows in-place interaction, it reduces hand movements and avoids cluttering the interface with menus and palettes. The device integrates seamlessly thanks to a visual programming interface, allowing end users to connect input and output sources in other existing software. We present various applications to demonstrate the power of VersaPen and how it enables new interaction techniques
link |
| 2016 | |
 |
SchemeLens: A Content-Aware Vector-Based Fisheye Technique for Navigating Large Systems Diagrams . Transactions on Visualization & Computer Graphics (TVCG), In InfoVis '15, 22, 1, IEEE (2016). 330-338.
@article{cohe:infovis15,
keywords
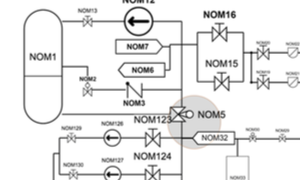
author = A. {Coh{\'e}} and B. {Liutkus} and G. {Bailly} and J. {Eagan} and E. {Lecolinet}, booktitle = InfoVis '15, journal = Transactions on Visualization \& Computer Graphics (TVCG), month = jan, number = 1, pages = 330--338, publisher = IEEE, title = SchemeLens: A Content-Aware Vector-Based Fisheye Technique for Navigating Large Systems Diagrams, volume = 22, year = 2016, hal = hal-01442946, image = cohe-infovis15.png, video = https://vimeo.com/152548517, rank = 0, } Fisheye; vector-scaling; content-aware; network schematics; interactive zoom; navigation; information visualization
abstract
System schematics, such as those used for electrical or hydraulic systems, can be large and complex. Fisheye techniques can help navigate such large documents by maintaining the context around a focus region, but the distortion introduced by traditional fisheye techniques can impair the readability of the diagram. We present SchemeLens, a vector-based, topology-aware fisheye technique which aims to maintain the readability of the diagram. Vector-based scaling reduces distortion to components, but distorts layout. We present several strategies to reduce this distortion by using the structure of the topology, including orthogonality and alignment, and a model of user intention to foster smooth and predictable navigation. We evaluate this approach through two user studies: Results show that (1) SchemeLens is 16-27% faster than both round and rectangular flat-top fisheye lenses at finding and identifying a target along one or several paths in a network diagram; (2) augmenting SchemeLens with a model of user intentions aids in learning the network topology. |
 |
LivingDesktop: Augmenting Desktop Workstation with Actuated Devices . In Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2016).
@inproceedings{GB:CHI16-living,
keywords
address = San Jose, USA, author = G. {Bailly} and S. {Sahdev} and S. {Malacria} and Th. {Pietrzak}, booktitle = Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = may, publisher = ACM, title = LivingDesktop: Augmenting Desktop Workstation with Actuated Devices, year = 2016, pdf = http://www.gillesbailly.fr/publis/BAILLY_LivingDesktop.pdf, hal = hal-01403719, image = GB-CHI16-living.jpg, video = https://www.youtube.com/watch?v=hC3hDlUIZ6s, } Augmented Desktop, Desktop Workstation, Actuated Devices Mouse, Keyboard, Monitor
abstract
We investigate the potential benefits of actuated devices for the desktop workstation which remains the most used environment for daily office works. A formative study reveals that the desktop workstation is not a fixed environment because users manually change the position and the orientation of their devices. Based on these findings, we present the LivingDesktop, an augmented desktop workstation with devices (mouse, keyboard, monitor) capable of moving autonomously. We describe interaction techniques and applications illustrating how actuated desktop workstations can improve ergonomics, foster collaboration, leverage context and reinforce physicality. Finally, the findings of a scenario evaluation are (1) the perceived usefulness of ergonomics and collaboration applications; (2) how the LivingDesktop inspired our participants to elaborate novel accessibility and social applications; (3) the location and user practices should be considered when designed actuated desktop devices. |
 |
TouchTokens: Guiding Touch Patterns with Passive Tokens . In Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2016). CHI 2016 Honorable Mention Award.
@inproceedings{RM:CHI16,
keywords
address = San Jose, USA, author = R. {Morales} and C. {Appert} and G. {Bailly} and E. {Pietriga}, booktitle = Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = may, publisher = ACM, title = TouchTokens: Guiding Touch Patterns with Passive Tokens, year = 2016, pdf = https://hal.inria.fr/hal-01315130/document, award = CHI 2016 Honorable Mention Award, hal = hal-01315130, image = RM-CHI16.jpg, video = https://www.youtube.com/watch?v=axe79jX_ZPw, } Tangible interaction, multi-touch input
abstract
TOUCHTOKENS make it possible to easily build interfaces that combine tangible and gestural input using passive tokens and a regular multi-touch surface. The tokens constrain users' grasp, and thus, the relative spatial configuration of fingers on the surface, theoretically making it possible to design algorithms that can recognize the resulting touch patterns. We performed a formative user study to collect and analyze touch patterns with tokens of varying shape and size. The analysis of this pattern collection showed that individual users have a consistent grasp for each token, but that this grasp is user dependent and that different grasp strategies can lead to confounding patterns. We thus designed a second set of tokens featuring notches that constrain users' grasp. Our recognition algorithm can classify the resulting patterns with a high level of accuracy (>95%) without any training, enabling application designers to associate rich touch input vo |
 |
Shared Interaction on a Wall-Sized Display in a Data Manipulation Task . In CHI'16: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM Press (2016). 2075-2086.
@inproceedings{LIU:CHI16,
keywords
author = C. {Liu} and O. {Chapuis} and M. {Beaudouin-Lafon} and E. {Lecolinet}, booktitle = CHI'16: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = may, pages = 2075--2086, publisher = ACM Press, title = Shared Interaction on a Wall-Sized Display in a Data Manipulation Task, year = 2016, hal = hal-01275535, image = LIU-CHI16.jpg, video = https://www.youtube.com/watch?v=X7IA9XFGL38, } Co-located collaboration; shared interaction; collaboration styles; wall-sized display; classification task; pick-and-drop
abstract
Wall-sized displays support small groups of users working together on large amounts of data. Observational studies of such settings have shown that users adopt a range of collaboration styles, from loosely to closely coupled. Shared interaction techniques, in which multiple users perform a command collaboratively, have also been introduced to support co-located collaborative work. In this paper, we operationalize five collaborative situations with increasing levels of coupling , and test the effects of providing shared interaction support for a data manipulation task in each situation. The results show the benefits of shared interaction for close collaboration: it encourages collaborative manipulation, it is more efficient and preferred by users, and it reduces physical navigation and fatigue. We also identify the time costs caused by disruption and communication in loose collaboration and analyze the trade-offs between parallelization and close collaboration. These findings inform the design of shared interaction techniques to support collaboration on wall-sized displays. |
| 2015 | |
 |
iSkin: Flexible, Stretchable and Visually Customizable On-Body Touch Sensors for Mobile Computing . In CHI'15: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, ACM (2015). 2991-3000. CHI 2015 Best Paper Award.
@inproceedings{GB:iskin-2015,
keywords
address = Seoul, Korea, author = M. {Weigel} and T. {Lu} and G. {Bailly} and A. {Oulasvirta} and C. {Majidi} and J. {Steimle}, booktitle = CHI'15: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, month = apr, pages = 2991--3000, publisher = ACM, title = iSkin: Flexible, Stretchable and Visually Customizable On-Body Touch Sensors for Mobile Computing, year = 2015, doi = http://dl.acm.org/citation.cfm?id=2702391, award = CHI 2015 Best Paper Award, image = GB-iskin-2015.png, project = http://embodied.mpi-inf.mpg.de/research/iskin/, video = https://youtu.be/9cvZnhvzrBI, bdsk-url-1 = http://dl.acm.org/citation.cfm?id=2702391, } On-body input; Mobile computing; Wearable computing; Touch input; Stretchable, flexible sensor; Electronic skin
abstract
We propose iSkin, a novel class of skin-worn sensors for touch input on the body. iSkin is a very thin sensor overlay, made of biocompatible materials, and is flexible and stretch- able. It can be produced in different shapes and sizes to suit various locations of the body such as the finger, forearm, or ear. Integrating capacitive and resistive touch sensing, the sensor is capable of detecting touch input with two levels of pressure, even when stretched by 30% or when bent with a radius of 0.5 cm. Furthermore, iSkin supports single or multiple touch areas of custom shape and arrangement, as well as more complex widgets, such as sliders and click wheels. Recognizing the social importance of skin, we show visual design patterns to customize functional touch sensors and allow for a visually aesthetic appearance. Taken together, these contributions enable new types of on-body devices. This includes finger-worn devices, extensions to conventional wearable de- vices, and touch input stickers, all fostering direct, quick, and discreet input for mobile computing.
project |
|
SuperVision: Spatial Control of Connected Objects in a Smart Home . In CHI Extended Abstracts: ACM Conference on Human Factors in Computing Systems, ACM (2015). 2079-2084.
@inproceedings{GOSH-ELC:CHI-EA15,
keywords
address = Soul, Korea, author = S. {Gosh} and G. {Bailly} and R. {Despouys} and E. {Lecolinet} and R. {Sharrock}, booktitle = CHI Extended Abstracts: ACM Conference on Human Factors in Computing Systems, month = apr, pages = 2079--2084, publisher = ACM, title = SuperVision: Spatial Control of Connected Objects in a Smart Home, year = 2015, hal = hal-01147717, video = http://sarthakg.in/portfolio/content-page-supervision.html, } Smart Home; Pico-projector; Spatial memory; Visualization; SuperVision
abstract
In this paper, we propose SuperVision, a new interaction technique for distant control of objects in a smart home. This technique aims at enabling users to point towards an object, visualize its current state and select a desired functionality as well. To achieve this: 1) we present a new remote control that contains a pico-projector and a slider; 2) we introduce a visualization technique that allows users to locate and control objects kept in adjacent rooms, by using their spatial memories. We further present a few example applications that convey the possibilities of this technique. |
|
| 2014 | |
 |
Effects of Display Size and Navigation Type on a Classification Task . In CHI'14: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2014). 4147-4156. CHI 2014 Best Paper Award.
@inproceedings{LIU-ELC:CHI14,
keywords
author = C. {Liu} and O. {Chapuis} and M. {Beaudouin-Lafon} and E. {Lecolinet} and W. {Mackay}, booktitle = CHI'14: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = apr, pages = 4147--4156, publisher = ACM, title = Effects of Display Size and Navigation Type on a Classification Task, year = 2014, award = CHI 2014 Best Paper Award, hal = hal-00957269, image = EffectDisplaySize-CHI14.jpg, video = http://www.youtube.com/watch?feature=player_embedded&v=SBXwW5lz-4o, bdsk-url-1 = http://dl.acm.org/citation.cfm?doid=2556288.2557020, } Wall-size display; Classification task; Physical navigation; Pan-and-zoom; Lenses; Overview+detail
abstract
The advent of ultra-high resolution wall-size displays and their use for complex tasks require a more systematic anal- ysis and deeper understanding of their advantages and draw- backs compared with desktop monitors. While previous work has mostly addressed search, visualization and sense-making tasks, we have designed an abstract classification task that involves explicit data manipulation. Based on our observa- tions of real uses of a wall display, this task represents a large category of applications. We report on a controlled experiment that uses this task to compare physical navigation in front of a wall-size display with virtual navigation using pan- and-zoom on the desktop. Our main finding is a robust interaction effect between display type and task difficulty: while the desktop can be faster than the wall for simple tasks, the wall gains a sizable advantage as the task becomes more dif- ficult. A follow-up study shows that other desktop techniques (overview+detail, lens) do not perform better than pan-and- zoom and are therefore slower than the wall for difficult tasks. |
 |
Multi-finger Chords for Hand-held Tablets: Recognizable and Memorable . In CHI'14: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2014). 2883-2892. CHI 2014 Honorable Mention Award.
@inproceedings{WAGNER-ELC:CHI14,
keywords
address = Toronto, Canada, author = J. {Wagner} and E. {Lecolinet} and T. {Selker}, booktitle = CHI'14: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = apr, pages = 2883--2892, publisher = ACM, title = Multi-finger Chords for Hand-held Tablets: Recognizable and Memorable, year = 2014, award = CHI 2014 Honorable Mention Award, hal = hal-01447407, image = MultiFingerChords-CHI14.jpg, video = https://www.youtube.com/watch?feature=player_embedded&v=W6aC9cqgrH0, bdsk-url-1 = http://dl.acm.org/citation.cfm?doid=2556288.2556958, } multi-finger chord; chord-command mapping; finger identification; hand-held tablet
abstract
Despite the demonstrated benefits of multi-finger input, todays gesture vocabularies offer a limited number of postures and gestures. Previous research designed several posture sets, but does not address the limited human capacity of retaining them. We present a multi-finger chord vocabulary, introduce a novel hand-centric approach to detect the iden- tity of fingers on off-the-shelf hand-held tablets, and report on the detection accuracy. A between-subjects experiment comparing 'random' to a `categorized' chord-command mapping found that users retained categorized mappings more accurately over one week than random ones. In response to the logical posture-language structure, people adapted to logical memorization strategies, such as `exclusion', `order', and `category', to minimize the amount of information to retain. We conclude that structured chord-command mappings support learning, short-, and long-term retention of chord-command mappings. |
| 2013 | |
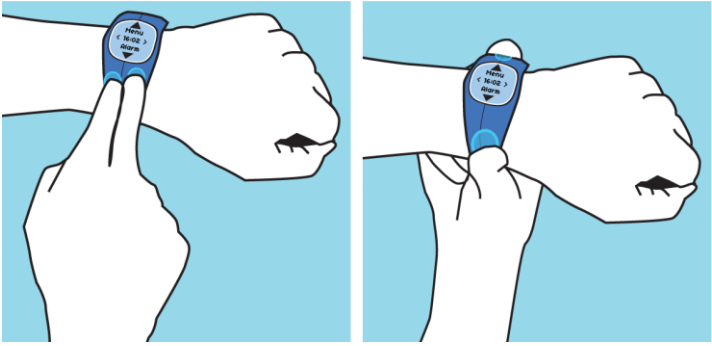 |
WatchIt: Simple Gestures and Eyes-free Interaction for Wristwatches and Bracelets . In CHI'13: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2013). 1451-1460.
@inproceedings{SP:2013,
keywords
address = Paris, France, author = S. T. {Perrault} and E. {Lecolinet} and J. {Eagan} and Y. {Guiard}, booktitle = CHI'13: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = apr, pages = 1451--1460, publisher = ACM, title = WatchIt: Simple Gestures and Eyes-free Interaction for Wristwatches and Bracelets, year = 2013, hal = hal-01115851, image = watchit.png, video = http://www.youtube.com/watch?feature=player_embedded&v=fDxmYJgD6Qw, bdsk-url-1 = http://dl.acm.org/citation.cfm?id=2466192&dl, } IHM; Digital jewelry; wearable computing; watch; watchstrap; watchband; watch bracelet; input; eyes-free interaction; continuous input; scrolling
abstract
We present WatchIt, a prototype device that extends interaction beyond the watch surface to the wristband, and two interaction techniques for command selection and execution. Because the small screen of wristwatch computers suffers from visual occlusion and the fat finger problem, we investigate the use of the wristband as an available interaction resource. Not only does WatchIt use a cheap, energy efficient and invisible technology, but also it involves simple, basic gestures that allow good performance after little training, as suggested by the results of a pilot study. We propose a novel gesture technique and an adaptation of an existing menu technique suitable for wristband interaction. In a user study, we investigate their usage in eyes-free contexts, finding that they perform well. Finally, we present a technique where the bracelet is used in addition to the screen to provide precise continuous control on lists. We also report on a preliminary survey of traditional and digital jewelry that points to the high frequency of watches and bracelets in both genders and gives a sense of the tasks people would like to perform on such devices. |
 |
Augmented Letters: Mnemonic Gesture-Base Shortcuts . In CHI'13: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2013). 2325-2328.
@inproceedings{QR:CHI-2013,
keywords
address = Paris, France, author = Q. {Roy} and S. {Malacria} and Y. {Guiard} and E. {Lecolinet} and J. {Eagan}, booktitle = CHI'13: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = apr, pages = 2325--2328, publisher = ACM, title = Augmented Letters: Mnemonic Gesture-Base Shortcuts, year = 2013, hal = hal-01164207, image = AugmentedLetters-CHI13.png, video = http://www.dailymotion.com/video/xxobz5_augmented-letters-mnemonic-gesture-based-shortcuts_tech, bdsk-url-1 = http://dl.acm.org/citation.cfm?id=2481321, } Interaction Design, Input and Interaction Technologies, Tactile Input, Language
abstract
We propose Augmented Letters, a new technique aimed at augmenting gesture-based techniques such as Marking Menus [9] by giving them natural, mnemonic associations. Augmented Letters gestures consist of the initial of command names, sketched by hand in the Unistroke style, and affixed with a straight tail. We designed a tentative touch device interaction technique that supports fast interactions with large sets of commands, is easily discoverable, improves user's recall at no speed cost, and supports fluid transition from novice to expert mode. An experiment suggests that Augmented Letters outperform Marking Menu in terms of user recall. |
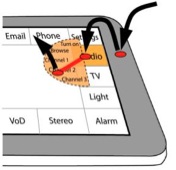 |
Bezel-Tap Gestures: Quick Activation of Commands from Sleep Mode on Tablets . In CHI'13: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, ACM (2013). 3027-3036.
@inproceedings{SERRANO:CHI-2013,
keywords
address = Paris, France, author = M. {Serrano} and E. {Lecolinet} and Y. {Guiard}, booktitle = CHI'13: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, month = apr, pages = 3027--3036, publisher = ACM, title = Bezel-Tap Gestures: Quick Activation of Commands from Sleep Mode on Tablets, year = 2013, hal = hal-01115852, image = BezelTap-CHI13.png, video = http://www.telecom-paristech.fr/~via/media/videos/bezel-tap-chi13.m4v, bdsk-url-1 = http://dl.acm.org/citation.cfm?id=2481421, } Interaction techniques; Mobile devices; Bezel Gestures; Accelerometers; Micro-Interaction; Marking Menus.
abstract
We present Bezel-Tap Gestures, a novel family of interaction techniques for immediate interaction on handheld tablets regardless of whether the device is alive or in sleep mode. The technique rests on the close succession of two input events: first a bezel tap, whose detection by accelerometers will awake an idle tablet almost instantly, then a screen contact. Field studies confirmed that the probability of this input sequence occurring by chance is very low, excluding the accidental activation concern. One experiment examined the optimal size of the vocabulary of commands for all four regions of the bezel (top, bottom, left, right). Another experiment evaluated two variants of the technique which both allow two-level selection in a hierarchy of commands, the initial bezel tap being followed by either two screen taps or a screen slide. The data suggests that Bezel-Tap Gestures may serve to design large vocabularies of micro-interactions with a sleeping tablet. |
| 2012 | |
 |
S-Notebook: Augmenting Mobile Devices with Interactive Paper for Data Management . In AVI'12: International Conference on Advanced Visual Interfaces, ACM (2012). 733-736.
@inproceedings{ELC:AVI-12,
abstract
address = Capri, Italy, author = S. {Malacria} and Th. {Pietrzak} and E. {Lecolinet}, booktitle = AVI'12: International Conference on Advanced Visual Interfaces, month = may, pages = 733--736, publisher = ACM, title = S-Notebook: Augmenting Mobile Devices with Interactive Paper for Data Management, year = 2012, hal = hal-00757125, image = SNotebook-AVI12.jpg, video = http://www.telecom-paristech.fr/~via/media/videos/s-notebook.m4v, } This paper presents S-Notebook, a tool that makes it possible to "extend" mobile devices with augmented paper. Paper is used to overcome the physical limitations of mobile devices by offering additional space to annotate digital files and to easily create relationships between them. S-Notebook allows users to link paper annotations or drawings to anchors in digital files without having to learn pre-defined pen gestures. The systems stores meta data such as spatial or temporal location of anchors in the document as well as the zoom level of the view. Tapping on notes with the digital pen make appear the corresponding documents as displayed when the notes were taken. A given piece of augmented paper can contain notes associated to several documents, possibliy at several locations. The annotation space can thus serve as a simple way to relate various pieces of one or several digital documents between them. When the user shares his notes, the piece of paper becomes a tangible token that virtually contains digital information. |
| 2011 | |
 |
Gesture-aware remote controls: guidelines and interaction techniques . In ICMI'11: ACM International Conference on Multimodal Interaction, ACM (2011). 263-270.
@inproceedings{GB:ICMI-11,
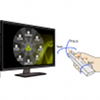
keywords
address = Alicante, Espagne, author = G. {Bailly} and D.-B. {Vo} and E. {Lecolinet} and Y. {Guiard}, booktitle = ICMI'11: ACM International Conference on Multimodal Interaction, month = nov, pages = 263--270, publisher = ACM, title = Gesture-aware remote controls: guidelines and interaction techniques, year = 2011, hal = hal-00705413, image = GestureAwareRemotes-ICMI11.png, video = https://www.youtube.com/watch?v=PfYwcCZapm4, } Mid-air gestures, remote control, 10-foot interaction, menu, interactive television
abstract
Interaction with TV sets, set-top boxes or media centers strongly differs from interaction with personal computers: not only does a typical remote control suffer strong form factor limitations but the user may well be slouching in a sofa. In the face of more and more data, features, and services made available on interactive televisions, we propose to exploit the new capabilities provided by gesture-aware remote controls. We report the data of three user studies that suggest some guidelines for the design of a gestural vocabulary and we propose five novel interaction techniques. Study 1 reports that users spontaneously perform pitch and yaw gestures as the first modality when interacting with a remote control. Study 2 indicates that users can accurately select up to 5 items with eyes-free roll gestures. Capitalizing on our findings, we designed five interaction techniques that use either device motion, or button-based interaction, or both. They all favor the transition from novice to expert usage for selecting favorites. Study 3 experimentally compares these techniques. It reveals that motion of the device in 3D space, associated with finger presses at the surface of the device, is achievable, fast and accurate. Finally, we discuss the integration of these techniques into a coherent multimedia system menu. |
 |
JerkTilts: Using Accelerometers for Eight-Choice Selection on Mobile Devices . In ICMI'11: ACM International Conference on Multimodal Interaction, ACM (2011). 121-128.
@inproceedings{MB:ICMI-11,
keywords
address = Alicante, Spain, author = M. {Baglioni} and E. {Lecolinet} and Y. {Guiard}, booktitle = ICMI'11: ACM International Conference on Multimodal Interaction, month = nov, pages = 121--128, publisher = ACM, title = JerkTilts: Using Accelerometers for Eight-Choice Selection on Mobile Devices, year = 2011, hal = hal-00705420, image = JerkTilts-ICMI11.png, video = http://www.telecom-paristech.fr/~via/media/videos/jerktilts.m4v, } Interaction techniques, handheld devices, input, accelerometers, gestures, Marking menu, self-delimited
abstract
This paper introduces JerkTilts, quick back-and-forth gestures that combine device pitch and roll. JerkTilts may serve as gestural self-delimited shortcuts for activating commands. Because they only depend on device acceleration and rely on a parallel and independent input channel, these gestures do not interfere with finger activity on the touch screen. Our experimental data suggest that recognition rates in an eight-choice selection task are as high with JerkTilts as with thumb slides on the touch screen. We also report data confirming that JerkTilts can be combined successfully with simple touch-screen operation. Data from a field study suggest that inadvertent JerkTilts are unlikely to occur in real-life contexts. We describe three illustrative implementations of JerkTilts, which show how the technique helps to simplify frequently used commands. |
 |
Flick-and-Brake: Finger Control over Inertial/Sustained Scroll Motion . In CHI Extended Abstracts: ACM Conference on Human Factors in Computing Systems, ACM (2011). 2281-2286.
@inproceedings{baglioni11-flickandbrake,
abstract
address = Vancouver, Canada, author = M. {Baglioni} and S. {Malacria} and E. {Lecolinet} and Y. {Guiard}, booktitle = CHI Extended Abstracts: ACM Conference on Human Factors in Computing Systems, month = may, pages = 2281--2286, publisher = ACM, title = Flick-and-Brake: Finger Control over Inertial/Sustained Scroll Motion, year = 2011, image = FlickAndBrake-CHI-EA11.png, video = http://www.telecom-paristech.fr/~via/media/videos/flick-brake.m4v, } We present two variants of Flick-and-Brake, a technique that allows users to not only trigger motion by touch-screen flicking but also to subsequently modulate scrolling speed by varying pressure of a stationary finger. These techniques, which further exploit the metaphor of a massive wheel, provide the user with online friction control. We describe a finite-state machine that models a variety of flicking interaction styles, with or without pressure control. We report the results of a preliminary user study which suggest that for medium to long distance scrolling the Flick-and-Brake techniques require less gestural activity than does standard flicking. One of the two variants of the technique is faster than state of the art flicking, while both are as accurate. Users also reported they preferred Flick-and-Brake techniques over the standard flick and judged it more efficient. |
| 2010 | |
 |
Finger-Count and Radial-Stroke Shortcuts: Two Techniques for Augmenting Linear Menus. . In ACM SIGCHI Conference on Human Factors in Computing Systems (CHI'10), ACM Press (2010). 591-594.
@inproceedings{GB:CHI-10,
keywords
address = Atlanta, USA, author = G. {Bailly} and E. {Lecolinet} and Y. {Guiard}, booktitle = ACM SIGCHI Conference on Human Factors in Computing Systems (CHI'10), month = apr, pages = 591--594, publisher = ACM Press, title = Finger-Count and Radial-Stroke Shortcuts: Two Techniques for Augmenting Linear Menus., year = 2010, image = FingerCount-CHI10.png, video = http://www.youtube.com/watch?feature=player_embedded&v=P69spTHzYUM, } menu techniques, multi-touch, multi-finger, two-handed interaction
abstract
We propose Radial-Stroke and Finger-Count Shortcuts, two techniques aimed at augmenting the menubar on multi-touch surfaces. We designed these multi-finger two-handed interaction techniques in an attempt to overcome the limitations of direct pointing on interactive surfaces, while maintaining compatibility with traditional interaction techniques. While Radial-Stroke Shortcuts exploit the well-known advantages of Radial Strokes, Finger-Count Shortcuts exploit multi-touch by simply counting the number of fingers of each hand in contact with the surface. We report the results of an experimental evaluation of our technique, focusing on expert-mode performance. Finger-Count Shortcuts outperformed Radial-Stroke Shortcuts in terms of both easiness of learning and performance speed. |
 |
Clutch-free panning and integrated pan-zoom control on touch-sensitive surfaces: the cyclostar approach . In ACM SIGCHI Conference on Human Factors in Computing Systems (CHI'10), ACM Press (2010). 2615-2624.
@inproceedings{SM:CHI-10,
keywords
address = Atlanta, GA, USA, author = S. {Malacria} and E. {Lecolinet} and Y. {Guiard}, booktitle = ACM SIGCHI Conference on Human Factors in Computing Systems (CHI'10), month = apr, pages = 2615--2624, publisher = ACM Press, title = Clutch-free panning and integrated pan-zoom control on touch-sensitive surfaces: the cyclostar approach, year = 2010, image = CycloStar-CHI10.png, video = https://www.youtube.com/watch?v=tcYX56TegbE#t=23, } Input techniques, touch screens, touchpads, oscillatory motion, elliptic gestures, panning, zooming, multi-scale navigation.
abstract
This paper introduces two novel navigation techniques, CycloPan, for clutch-free 2D panning and browsing, and CycloZoom+, for integrated 2D panning and zooming. These techniques instantiate a more generic concept which we call Cyclo* (CycloStar). The basic idea is that users can exert closed-loop control over several continuous variables by voluntarily modulating the parameters of a sustained oscillation. Touch-sensitive surfaces tend to offer impoverished input resources. Cyclo* techniques seem particularly promising on these surfaces because oscillations have multiple geometrical and kinematic parameters many of which may be used as controls. While CycloPan and CycloZoom+ are compatible with each other and with much of the state of the art, our experimental evaluations suggest that these two novel techniques outperform flicking and rubbing techniques. |
 |
Wavelet menus on handheld devices: stacking metaphor for novice mode and eyes-free selection for expert mode . In In AVI'10: International Conference on Advanced Visual Interface, ACM Press (2010). 173-180.
@inproceedings{GB:AVI-10, author = J. {Francone} and G. {Bailly} and E. {Lecolinet} and N. {Mandran} and L. {Nigay}, booktitle = In AVI'10: International Conference on Advanced Visual Interface, month = may, pages = 173--180, publisher = ACM Press, title = Wavelet menus on handheld devices: stacking metaphor for novice mode and eyes-free selection for expert mode, year = 2010, image = WaveletMenu-AVI10.png, video = http://www.telecom-paristech.fr/~via/media/videos/wavelet-menu.m4v, } |
| 2009 | |
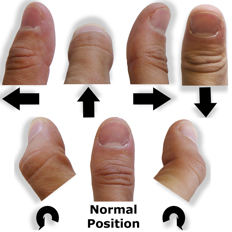 |
MicroRolls: Expanding Touch-Screen Input Vocabulary by Distinguishing Rolls vs. Slides of the Thumb . In ACM CHI (Conference on Human Factors in Computing Systems), (2009). 927-936.
@inproceedings{RA:CHI-09,
keywords
address = Boston, USA, author = A. {Roudaut} and E. {Lecolinet} and Y. {Guiard}, booktitle = ACM CHI (Conference on Human Factors in Computing Systems), month = apr, pages = 927--936, title = MicroRolls: Expanding Touch-Screen Input Vocabulary by Distinguishing Rolls vs. Slides of the Thumb, url = http://dl.acm.org/citation.cfm?doid=1518701.1518843, year = 2009, image = MicroRolls-CHI09.png, video = http://www.youtube.com/watch?feature=player_embedded&v=bfH0-OqgbLw, bdsk-url-1 = http://dl.acm.org/citation.cfm?doid=1518701.1518843, } Mobile devices, touch-screen, interaction, selection techniques, gestures, one-handed, thumb interaction, rolling/sliding gestures, MicroRoll, RollTap, RollMark. |
 |
TimeTilt: Using Sensor-Based Gestures to Travel Through Multiple Applications on a Mobile Device . In Interact (IFIP Conference in Human-Computer Interaction), (2009). 830-834.
@inproceedings{RA:INTERACT-09,
keywords
address = Uppsala, Su{\`e}de, author = A. {Roudaut} and M. {Baglioni} and E. {Lecolinet}, booktitle = Interact (IFIP Conference in Human-Computer Interaction), month = aug, pages = 830-834, title = TimeTilt: Using Sensor-Based Gestures to Travel Through Multiple Applications on a Mobile Device, url = http://link.springer.com/chapter/10.1007%2F978-3-642-03655-2_90, year = 2009, image = TimeTilt-INTERACT09.png, video = http://www.youtube.com/watch?feature=player_embedded&v=7JBSpojUBm8, bdsk-url-1 = http://link.springer.com/chapter/10.1007%2F978-3-642-03655-2_90, } Mobile devices, sensors, interaction techniques, multiple windows |
 |
Leaf Menus: Linear Menus with Stroke Shortcuts for Small Handheld Devices . In Interact (IFIP Conference in Human-Computer Interaction), (2009). 616-619.
@inproceedings{BG:INTERACT-09,
keywords
address = Uppsala, Su{\`e}de, author = A. {Roudaut} and G. {Bailly} and E. {Lecolinet} and L. {Nigay}, booktitle = Interact (IFIP Conference in Human-Computer Interaction), month = aug, pages = 616--619, title = Leaf Menus: Linear Menus with Stroke Shortcuts for Small Handheld Devices, url = http://link.springer.com/chapter/10.1007%2F978-3-642-03655-2_69, year = 2009, image = LeafMenus-INTERACT09.jpg, video = http://www.youtube.com/watch?feature=player_embedded&v=bsswQ06pZrU, bdsk-url-1 = http://link.springer.com/chapter/10.1007%2F978-3-642-03655-2_69, } Mobile devices, gestures, menu, interaction techniques
abstract
This paper presents Leaf menu, a new type of contextual linear menu that supports curved gesture shortcuts. By providing an alternative to keyboard shortcuts, the Leaf menus can be used for the selection of commands on tabletops, but its key benefit is its adequacy to small handheld touchscreen devices (PDA, Smartphone). Indeed Leaf menus define a compact and known layout inherited from linear menus, they support precise finger interaction, they manage occlusion and they can be used in close proximity to the screen borders. Moreover, by providing stroke shortcuts, they favour the selection of frequent commands in expert mode and make eye-free selection possible. |
| 2001 | |
|
Zoomable and 3D Representations for Digital Libraries . In Conférence franco-britannique IHM-HCI (Interaction Homme-Machine / Human Computer Interaction),, (2001).
@inproceedings{reference124, address = Lille, author = P. {Plenacoste} and E. {Lecolinet} and S. {Pook} and C. {Dumas} and J.-D. {Fekete}, booktitle = Conf\'erence franco-britannique IHM-HCI (Interaction Homme-Machine / Human Computer Interaction),, month = sep, title = Zoomable and 3D Representations for Digital Libraries, year = 2001, video = http://www.telecom-paristech.fr/~elc/videos/biblinum.mov, } |
|
| 2000 | |
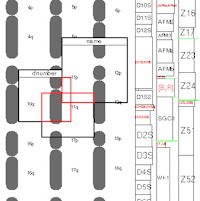 |
Context and Interaction in Zoomable User Interfaces . In International Conference on Advanced Visual Interfaces (AVI'200), ACM Press (2000). 227-231.
@inproceedings{reference194, address = Palerme (Italie), author = S. {Pook} and E. {Lecolinet} and G. {Vaysseix} and E. {Barillot}, booktitle = International Conference on Advanced Visual Interfaces (AVI'200), month = may, pages = 227--231, publisher = ACM Press, title = Context and Interaction in Zoomable User Interfaces, year = 2000, image = Zomit-AVI00.jpg, video = http://www.telecom-paristech.fr/~elc/videos/zomit.mov, } |
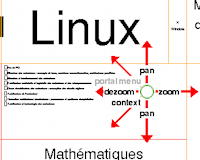 |
Control Menus: Execution and Control in a Single Interactor . In ACM SIGCHI Conference on Human Factors in Computing Systems (CHI'2000), (2000). 263-264.
@inproceedings{reference196, address = The Hague (The Netherlands), author = S. {Pook} and E. {Lecolinet} and G. {Vaysseix} and E. {Barillot}, booktitle = ACM SIGCHI Conference on Human Factors in Computing Systems (CHI'2000), month = apr, organization = ACM Press, pages = 263--264, title = Control Menus: Execution and Control in a Single Interactor, year = 2000, image = Zomit-CHI00.jpg, video = http://www.telecom-paristech.fr/~elc/videos/zomit.mov, rank = 2, } |